Writing an AI for a turn-based game
The question of whether a computer can think is no more interesting than the question of whether a submarine can swim. Edsger Dijkstra
I took the last week off work to try to make a video game. While the game is still a work in progress, I really enjoyed making the AI for it. And I think the AI turned out really well.
You can see a demo here of the final product
The game
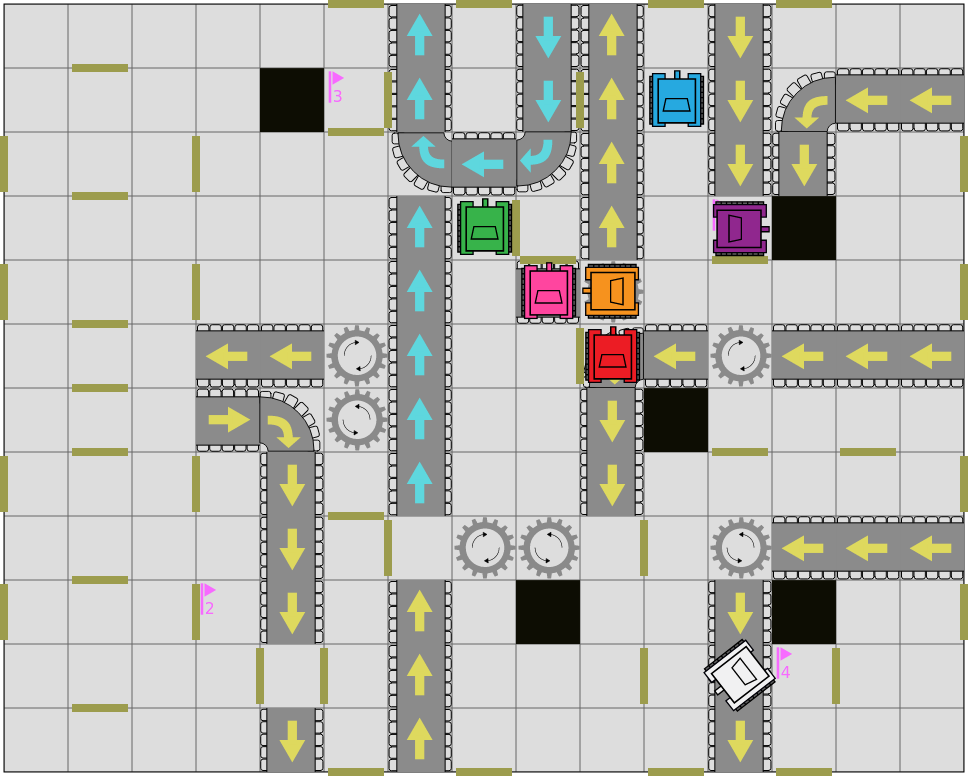
Automatank (working title) is a turn-based robot programming game. It’s inspired by one of my favourite board games: RoboRally.
Each player is given 9 random moves. The player then picks 5 of these moves and arranges them in an order for the robot to execute. Each move either moves the robot forward, moves it backward, or rotates the robot.
There are hazards along the way: walls, conveyors belts, bottomless pits, and other obstacles.
The goal is to capture all the flags before the other robots.
A Basic AI
A game AI isn’t an AI in the machine learning sense. It’s just a program which attempts to play a game in a semi-competant way.
The AI I’m writing needs to try to determine the best move it can make based on the current game state.
It can be tempting, when faced with a task like this, to try to encode the behaviours a human would make when playing the game. Things like:
- Turn towards the next flag if you aren’t facing it
- Move forward if facing the next flag
This approach doesn’t really work. There may be walls or hazards in the way. The AI may not have the moves it needs. Writing special cases for these quickly explodes in complexity and isn’t really feasible.
Instead what I do is consider all possible hands and pick the best one.
This approach is good. Something similar should work for most turn based games. The challenge is how to score each hand.
In order to evaluate how good a hand is, the AI needs to be able simulate the outcome of that hand and then picking the best outcome.
Fortunately, I kept this in mind when writing the game itself. The code which simulates the game can be run standalone and I can reuse this for the AI.
Here’s the first attempt at an AI
This works (somewhat). The AI simulates its potential choices so it definitely won’t pick commands which lead to it’s death. If it comes across a hand which will have it collect another flag, it will do that. Aside from that, it will move randomly (but safely).
Pathing
Since the simulation only looks one turn ahead, the behaviour doesn’t seem “intelligent”. If it doesn’t see a way to collect a flag in one turn, it just moves randomly.
The AI doesn’t know what moves it will get next round, so it can’t simulate past the current hand. Even if it could it would be too slow (exponentially) to test all future hands until it could find a flag.
Instead what I did is gave it better hints of when it is making progress towards the goal.
One quick obvious heuristic we use is trying to reduce the distance between the robot and the flag.
This is much better. Instead of meandering until they randomly become close to a flag, the AI immediately tries to close it’s distance with the flag.
It’s not without issues. Although the short term planning understands the workings of walls and conveyors, the long term planning doesn’t. This is pretty apparent when the robot comes across a large wall in-between it and the flag. To a human player it’s obvious to just go around, but our Manhattan distance metric doesn’t give us any help here.
To have better pathing, we can use the shortest path as a metric instead.
Using shortest path we can answer the question “if I get all the moves I need, how many moves will it take to reach the flag?”.
Shortest Path
To solve for the shortest path, I used a breadth-first search (BFS). But I think it’s useful to consider to consider this a simplified case of Dijkstra’s algorithm.
With BFS we visit nodes in a queue. We start at the source node and add its immediate neighbours. These neighbours (at a distance of 1 from our source) are visited and their unvisited neighbours are added to the queue. We continue this way until we arrive at the destination, and return its distance.
In the case of this game, the nodes represent the possible positions of our robots (x, y, and direction) and the node’s neighbours are other positions which can be reached in one turn.
Once again we’re able to reuse our method to simulate the game.
The AI is now eerily smart.
They can navigate mazes. They will seek out conveyor belts that will move them closer to the flag. Since each direction is its own node it will even try to end the turn pointing in a good direction in anticipation of the next turn.
It’s a bit slow, though.
Precomputing distances
What was previously a few simple math operations is now running a full simulation of the game from (potentially) every single position on the board. The AI needs to do 100 times per turn!
I could use A* or add some caching, both of which would be faster. But what I’d really like is to precompute the paths, so that the scoring function can be constant time again.
There are algorithms to calculate all pairs shortest path, but this is a bit slow and needs a bit too much storage: for a 30-by-30 map (30 * 30 * 4) ** 2 == 12960000 12 megabytes even if stored as bytes.
Fortunately, the AI doesn’t need paths between all pairs, just paths leading to the four flags on the map.
It happens that Dijkstra’s Algorithm (or the simpler BFS variant) actually solves all paths from one source to any destination. So it does exactly what we need, only backwards. To use this I generate an adjacency list by doing a simulation of every move from every possible starting position. Then I run BFS from the flag and storing distances each time it visits a new position until it has stored.
This is pretty much instant, and can be done once when the game loads and shared among all AIs.
Conclusion
I really like how this AI turned out. Strategies don’t need to be explicitly defined but can be inferred by reusing the game’s implementation.
Watch some AIs duke it out: http://automatank.butt.team/demo
Or play against them at: http://automatank.butt.team/versus_ai